
Researchers at Stanford invented a way to use transformers for robot motion planning with visual feedback called Action Chunking with Transformers (ACT). Action chunking is a concept from psychology that describes how our brain groups sequences of actions together as a chunk and executes the whole thing as a unit. They demonstrated that using this technique in robotics can significantly improve autonomous task performance because it reduces the opportunity for motion errors to compound over time. What follows is a description of the network architecture used for ACT.
Transformer Neural Networks
Transformer neural networks are the same technology behind large language models like ChatGPT, but in robotics, instead of predicting sequences of words or language tokens, they predict sequences of actions or motor control signals. Transformer neural network are explained in the paper Attention is All You Need released by researchers at Google in 2017. The key insight behind transformers was that “attention heads” could be used to encode long range relationships between features — whether words or groups of image pixels — that occur in some kind of sequence.
The attention mechanism described in the 2017 paper is a key insight and it shifted the entire field of AI away from recurrent connections in deep neural networks (RNNs or LSTMs). The generic name for objects that occur in a sequence (in the context of transformers) is a “token”, and the optimal token at a given position depends on the context (other tokens) that surround it. Attention heads in transformers are sets of weights that define how important other tokens in the surrounding context are for the current inference task. The correct distribution of attention for a given token is calculated by matching a query to a set of keys. Each key is associated with a corresponding value, so finding the matching key for a query is akin to looking up a value in a dictionary data structure.
Understanding the Purpose of Encoders and Decoders
An excellent explanation of the origin of encoders and decoders comes from this 2023 Andrej Karpathy lecture at Stanford. In this video Andrej discusses a paper from 2014 called Sequence to Sequence Learning with Neural Networks. At the time they had very basic neural networks with predictive capability, so they could take a sequence of 3 words and predict the 4th. They wanted to apply this to machine translation, which became more complex. So you no longer have 3 words and predict the 4th you are now taking an arbitrary number of words in English and predicting an arbitrary number of words in French, so how do you process this variably sized input? This was where the encoder-decoder architecture was proposed. So the encoder acts a memory and consumes one word at a time and gathers the context of what it has read, then feeds it as a conditioning vector for the decoder which then predicts the French word based on the context.
In our robotics application, the query is a sinusoidal position code that represents a particular place in an image. Keys and values are relevant information, from the current joint positions and camera views, that is organized into a kind of dictionary by the transformer encoder during the training process. The input to the encoder is the camera data (with positional embeddings, and encoded into features using ResNet18 CNNs) along with the current motor positions and a “style variable” (described later). The output is this dictionary that can be used by the transformer decoder to predict output actions. The dictionary is constantly updated by the changing current camera data and motor positions, so the keys and values evolve over time and are always relevant to the current state of the robot. However, all the possible keys and values are stored by the neural network weights during the training phase.
Transformers for Motion Planning
ALOHA stands for A Low-cost Open-source Hardware System for Bimanual Teleoperation, developed and published by researchers at Stanford University. In this project, Stanford researchers demonstrated the ability to utilize Transformer Neural Networks for robotic motion planning.
Action Chunking with Transformers
Action Chunking with Transformers (ACT) trains a transformer encoder (separate from the transformer encoder used to create the key/value dictionary) to output what they describe as a style variable. I think of it as a sort of grade of the human demonstration. Consider that a human performing a task may do it slightly differently each time, pausing at different moments or perhaps moving the arms along different paths when the exact route is not critical to the task. This makes the training data seem stochastic, and the algorithm must learn to ignore differences in training demonstrations that don’t really matter. The Stanford ALOHA researchers found this technique to be crucial for training a robot skill by imitating human examples. The style variable is regularized to approximate a diagonal gaussian probability distribution, thereby creating the requisite bottleneck. An ideal demonstration should achieve a grade of zero, exactly at the mean of the gaussian bell curve shape. During inference at test time, the style variable is set to a constant zero value. That lets the network know to deterministically output the most ideal action sequence that it knows how to produce.
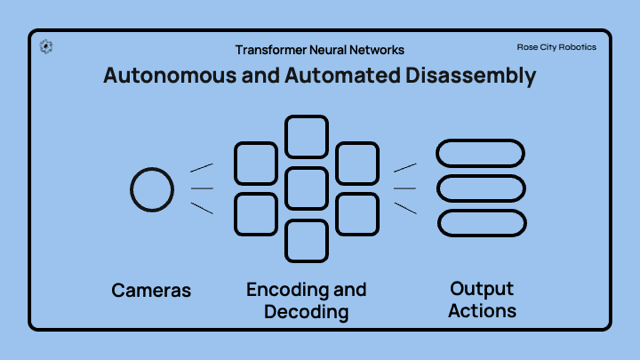
The above diagram shows how we utilize cameras to feed data to the neural network. If we use the example of the encoder and decoders used for translation above, in robotics we are taking a slice of video data from a set of human teleoperation examples, encoding that data in context, and then using the decoder to “translate” the visual information into a prediction of the next set of motor control signals needed to drive the output actions. So for example “see a fastener like a screw” and translate that to take the action to “move the screwdriver towards the screw” because that is the action the neural network has learned from observing the human worker in a similar situation.
How we are using Transformer Neural Networks
At Rose City Robotics, we have a working prototype based on the open-source Stanford robot ALOHA parts list and assembly tutorial we call RoZero Bot (RoZe).
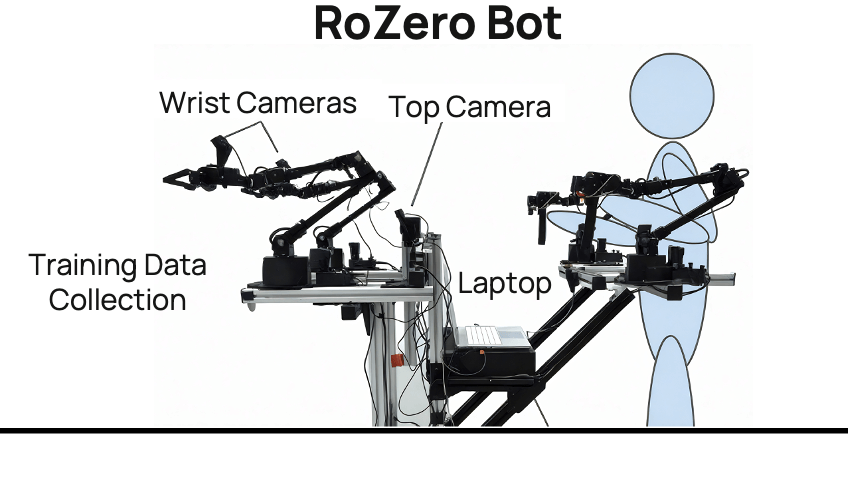
With RoZe, a human operator teleoperates two robotic arms and gripper end effectors to perform a task. RoZe is equipped with three onboard cameras, one on each wrist and one on the main body as well as a laptop which together capture motion and joint data. With a dataset of 50-100 examples, we can train a Transformer Neural Network to perform a task autonomously with up to 90% accuracy.
